07 — Character Strings

07 — Character Strings
The video introduced the very popular and very simple null terminated character strings, and this web page goes deeper. It will also introduce the important idea of code libraries.
With its memory limitations, ArdEx isn't going to suit writing a word processor, but we can still use it to see what goes on inside strings. It's just the same in larger computers.
The idea of a null terminated string is just like the idea of ending a sentence with a full-stop (period). You know where it starts, and a special character tells you where it ends.
In the video I used the special null character ␀ to represent an ASCII null byte. This may not show up correctly in all browsers. Since null terminated strings were popularised by C, I'll use the C convention of null being represented by \0 (backslash-zero).
The video started by storing Hello\0 in six bytes of RAM. It then extended it to Hello, World!\0, and finally chopped this into the two strings Hell\0 and , World!\0. So that's the highlights of the video in two sentences and there really isn't much more to know about how strings are stored. The interesting part is how you use them. We'll get to that soon.
In times gone by, a byte value of 3 represented "End of Text" (ETX) on communications lines. We could still use that, but using a zero byte means that the CPU's Z flag can be tested on many processors. Interestingly, the byte value of 3 is what you get when you type <Ctrl>-C. So the old end-of-text character is now often used to end a program.
Another string representation is to enclose strings in quotation marks. Computer languages use this in source code to keep strings distinct from other language elements.
printf("Hello, World!\n");
Quoted strings usually have special rules for when you want to include
one of the quote characters within the string.
Most importantly, there are counted strings. Rather than have a terminating character, the very first thing in the string is the number of characters that follow.
| 13 | H | e | l | l | o | , | W | o | r | l | d | ! |
Counted strings have a lot of appeal. It seems so much nicer to know the length of the string right up front. I used to feel that way (and I see whoever wrote the WikiPedia page on null terminated strings still feels that way), but it doesn't take long using counted strings before you get a feel for their problems:
ASCII is an old standard, but it is very widely supported. It's fine for writing English, but lacks support for acutes, graves, umlauts and other accents used in various European languages.
As you've probably noticed, ASCII only uses 7 bits, so there's one bit to spare in each byte. The extra bit was once used as a parity bit, but communications tend to be reliable these days, so the extra bit has been used to provide another block of characters. There have been various different encodings used, but ISO 8859-1 is popular and covers what you need for Spanish, French and German.
That deals with the simple languages, but other languages can have thousands of symbols and have no chance of being represented in a byte. There have been various evolving standards of multibyte character sets, and everything seems to be converging on Unicode.
Getting into that is well beyond the scope of ArdEx. Using multibyte characters sends more or less everything I'm saying here out the window. However, I confidently predict that single byte characters will be with us for a long time to come (good old ASCII is the first 128 slots of every unicode encoding). The examples here will stay relevant.
ArdEx is good for demonstrating just how computer software works at the lowest levels. However, even assembly language programmers don't write all their code at this low level. In the dice simulator, we used functions to generate the random dice values, and to display the results. The higher level code more or less glued together calls to those functions.
The dice functions were specific to that problem, but it's easy to think of functions that you might use again and again in different programs: print a string, get a string from the keyboard, join two strings, etc. In years gone by, a programmer kept chunks of reusable code, typically in decks of punched cards, and would insert them into later programs as they were needed. Eventually this idea was automated and the function library was created.
A function library contains code for a number of functions. A program can be linked with this library. This means that any functions which are called by the program code, but aren't defined by that code will be automatically extracted from the library and included in the final program.
This was much easier than effectively cutting and pasting the original code into each program that used it. It also helped with teams of programmers who would agree on particular library functions which helped them to understand each other's programs. Gradually these in-house libraries have been combined to make standard libraries. You can now go from one team to another already understanding these standard functions (though each team will build their own higher-level libraries, so it can still be hard work changing teams).
Here are outlines of some of the standard C library functions related to string handling.
This is a "Swiss army knife" function, and an example of a well thought out idea. I'll not go into much depth, but in outline, the format string is really a tiny programming language. The function uses the format string to decide how to interpret each of the subsequent arguments.
For example, when the next characters in the format string are %c, say the next argument is 66, a letter B (ASCII 66) will be copied to the memory. If, instead, there had been a %d, 66 (a pair of sixes) would have been copied to the memory. I.e. %c interprets the value as a character, and %d interprets it as a decimal number.
It's a good line of attack on many programming problems to see if you can come up with a language which expresses the solution more clearly than the language you're working with. The format string is a good example of this.
Unfortunately sprintf is too complicated to write within ArdEx. Below you will see some number-to-string conversions have been included in the library, but there's no fancy formatting language.
If you think about it, you could use sprintf to implement strlen, strcpy, and strcat. I hope you can see why doing this doesn't appeal to me.
The original plan with ArdEx was to use it to introduce only the lowest-level aspects of programming. Using library functions is at least one step up from this. I changed plans and have modified aasm so it can extract function code as necessary from a library. This does make ArdEx more productive, but risks being less instructive. To avoid this, I suggest you look at the library code or, better still, write your own version of whichever library function(s) you use. See if you can improve on my versions (which, I admit, were thrown together quickly).
For example, think how you would implement strrchr. On the surface you might think of going to the last character in the string and then searching backwards. That's not so smart because you had to search forwards to find the null at the end of the string. Do you really need to look backwards again, having passed the character going forwards?
If you look at the library code you'll see that "official" entry points have been prefixed with a percentage sign (e.g. %puts) and that functions within the library may call other functions in the library. You don't need the percentage sign when calling library functions.
I should mention that library support has been tacked on. It's reasonably flexible, but not as powerful as true object code library
Programmers in other languages don't need to worry about these sorts of conventions because the writers of the language compiler have already made the decisions. For example some C compilers pass their arguments first argument first, others pass them last argument first (i.e. in reverse order). The C programmer doesn't need to worry about which it is (well, at least not as long as they stick to C and that compiler).
There is a C convention that the address 0 is never valid. This allows a function like strchr to use a pointer value of zero to indicate that it failed to find the character. As you probably know, 0 is a perfectly valid RAM address in ArdEx (and many other computers), but we'll stick to the C convention for these functions. It'll still be fine to use address 0 for lookup tables and so on, but be careful using it with library functions.
This zero pointer value is known as a NULL pointer. That's legitimate, but has led to a lot of confusion. You can have a null character, a pointer to a null character, or a null pointer. They're three different things, but the similar names have confused many learners. It might have been better to have called it an INVALID pointer, but it's too late now.
The ArdEx library includes most of the standard string functions listed above, along with a few non-standard ones.
If you look at the library code you'll see that the functions
gets and getc have
been complicated by several things:
An operating system would usually look after these things, but we're working down at the machine level. The gets library function ends up being quite large, but very handy.
Let's start with the example from the video: trim leading blanks from a string. You enter a string at the keyboard. The string is echoed back to you without any leading blanks.
; ; Accept a string from the terminal and print it with leading spaces removed. ; loop: MOV #0xe0,R0 ; buffer for user input MOV #25,R1 ; allow 25 characters CALL gets ; get the string CALL ltrim ; trim it CALL puts ; print it JMP loop ltrim: CMP #0,@R0 ; end of the string? JEQ gohome CMP #' ',@R0 ; a space? JNE gohome ADD #1,R0 ; point to next character JMP ltrim gohome: RET
The main loop is just one CALL after another. There's not much need to shuffle registers around because the standard functions leave their arguments alone.
The ltrim function steps R0 forward over spaces, but is careful not to step past the end of the string (e.g. if the string is all spaces).
You can assemble the function using:
Click to download the source ltrim.adx or, if you want to skip the assembler, the assembled code ltrim.txt.
Here'a an easy one. Accept a string from the command line and print the number of characters in that string.
; ; Accept a string from the terminal and print its length. ; loop: MOV #0xe0,R0 ; input buffer MOV #32,R1 ; maximum length CALL gets CALL strlen ; length in R24 MOV R24,R1 CALL numtostr ; reuse input buffer for output CALL puts ; print the result JMP loop
This time it's all join-the-dots code using library functions. Assemble it in the same way as ltrim. Source: length.adx; assembled: length.txt.
This one's a bit trickier. Accept a string from the command line and print the number of words and the number of characters in the string. There's some fancy footwork going on here, so there's more to explain.
; ; Accept a string from the terminal and count words and characters. ; loop: MOV #0xe0,R0 ; base of input buffer MOV #32,R1 ; maximum length CALL gets ; get string from user MOV #0,R1 ; count of words CALL wc ; # words in R1 MOV R0,R2 ; end of buffer in R2 MOV #0xe0,R0 ; base of buffer SUB R0,R2 ; total string length in R2 CALL numtostr ; convert word count to string CALL putstr ; print it OUT ' ' ; a space MOV R2,R1 CALL numtostr ; convert character count to string CALL puts ; print it with a newline JMP loop wc: MOV #skipbl,R2 ; code pointer!! cont: CMP #0,@R0 ; end of the string? JNE R2 ; jump to code RET skipbl: ; skipping over blanks CMP #' ',@R0+ ; leading space? JEQ cont ; yes -- continue ADD #1,R1 ; first non-space character. New word. MOV #skipnbl,R2 JMP cont skipnbl: ; skipping over non-blanks CMP #' ',@R0+ ; scan ahead to next space JNE cont ; still skipping non blanks JMP wc ; back to initial state
The top-level loop is easy enough to understand: read a line from the user, calculate the number of words and the length, then print those values. The only clever part is that we don't bother with strlen to work out the length. Since we know wc has reached the null at the end of the string, the length is just this pointer minus the address of the start of the string.
The wc (short for "word count") function is a different matter. What's going on with its first line, for example? We'll come to that. Let's start by thinking about the problem.
You want to count "words" in a line of text. What is a word? I suggest you look away and think about it...
The definition I have used is that a word is any cluster of
non-blank characters. Clusters of one or more blank characters
separate words, and, of course, the whole string ends with a null
character.
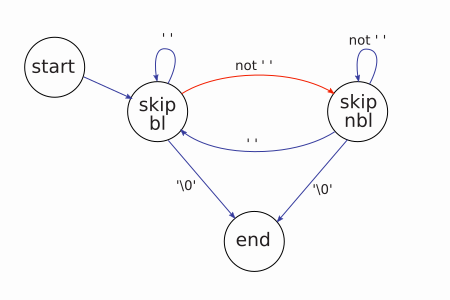
This can be visualised as a state transition diagram. At the start of the string, you want to skip over any blanks so you go straight into the skipbl state. As soon as you see a character that is not a blank, you enter the skipnbl state to skip over further non-blank characters. If you then see a blank, it's back into the skipbl state. And regardless of which state you're in, the moment the null character is seen, you're at the end.
State transition diagrams usually show only what causes states to change, but don't say what to do when that happens. However, wc is so simple that there is only one transition with a side-effect. The red one. What happens then? It's the first character of a new word. The word count increases by 1.
The diagram might help you to understand what the wc function is doing. The programming trick here is to use a pointer to some code to represent the state. We haven't used a register as a jump target before, but it does exactly what you might think. It takes the value in the register, and jumps to that slot. Very dangerous, but very powerful!
We start with a pointer to the skipbl code in R2. The loop always starts by checking if the character is a null. If not, it jumps to whichever code snippet R2 is pointing at.
In the case of skipbl, a blank means it just continues the loop. When it sees a non-blank, it bumps up the word count and switches state to skipnbl
In the skipnbl state, it continues the loop for non-blanks. It's a bit clever in that, when it sees a blank, it jumps all the way back to the start, reusing code that already sets state to skipbl.
I am afraid some experienced programmers wouldn't applaud this approach. Code that hops around like this is against all the rules of structured programming. I agree. However, here is a nicely structured C version of wc:
int
wc(const char *buf)
{
enum state state = SKIPBL;
int nw = 0;
while (*buf)
{
switch (state)
{
case SKIPBL:
if (!isspace(*buf++))
{
state = SKIPNBL;
nw++;
}
break;
case SKIPNBL:
if (isspace(*buf++))
state = SKIPBL;
break;
}
}
return(nw);
}
A good C compiler is very likely to turn this function into just the same kind of "hopping around" assembly language code. The computer's quite at home with it. It is good to understand what the machine is really doing.
Incidentally, you might have noticed that the C code is using isspace to test for blanks. This returns true for any whitespace character (e.g. tab) not just space. There are a whole raft of these functions: isdigit, ispunct, isalpha, isalnum, isupper, islower, and others. I'm sure you can work out what they do from the names. How do you think they work?
Well done if you said a look up table with 256 slots. One bit in each slot indicates whether it is an ASCII digit. A different bit would say that that character is lower-case. Etc. The isalnum test would use the byte given to look up the table and it would return true if any of the digit, upper-case or lower-case bits is set.
At least that applies to 8-bit characters. It'd need a larger table to deal with multibyte characters, and lots else besides. Does upper-case mean anything in Chinese?
This example gets a line of text from the user and reverses it in-situ. I suggest you have a go at writing this one for yourself before seeing mine.
; ; Accept a line from the keyboard and print it with its ; characters reversed. ; mainloop: MOV #0xe0,R0 MOV #32,R1 CALL gets CALL reverse MOV #0xe0,R0 CALL puts JMP mainloop reverse: MOV R0,R1 ; R0 => start of string seeknull: CMP #0,@R1+ JNE seeknull SUB #1,R1 ; R1 => null at end of string JMP reventry revloop: MOV @R0,R2 ; char from head in R2 MOV @-R1,@R0+ ; char from tail to head MOV R2,@R1 ; original head to tail reventry: CMP R1,R0 JC revloop RET
The top level loop is much as usual.
If you think how you might reverse the letters in line of Scrabble tiles, the reverse function works much the same way. It sets pointers to the two ends of the string, exchanges bytes at the ends, then moves the pointers one step towards the middle. This is continued until the pointers meet at the middle.
A couple of tricky aspects. R2 is used as temporary storage. Store the front character there for a moment, then copy the back character to the front, and finally write the value from R2 to the back.
We've used postincrement before. There is only predecrement available (i.e. it subtracts 1 from the register before accessing the memory). This is sorted out by starting pointing to the null rather than the last character.
Another tricky thing is the end condition. This code is spot-on for even-length strings. For odd-length strings, the centre byte will be copied over itself. This does no harm, and requires less code than if we checked for R0 ≥ R1 − 1.
As a last, rather silly example, we'll accept a word from the user and convert it into Pig Latin. The rules of Pig Latin are fairly simple. If the word starts with a consonant, you move the leading consonants to the end of the word and append "ay". For example, the word "string" becomes "ingstray". If the word starts with a vowel, append "way" to it. E.g. "ArdEx" becomes "ArdExway".
; ; Pig latin converter. Enter a word, convert it to pig latin. ; start: MOV #0xe0,R0 MOV #16,R1 CALL gets ; get string from user. MOV #' ',R1 CALL strchr ; make sure there are no embedded spaces JEQ good MOV #0,@R24 ; null terminate first word good: CALL strlen MOV R0,R1 ADD R24,R1 ; point R1 to null at end of word xferloop: CALL vowel JEQ gotvowel ; ; Consonant first -- append consonants to end of word ; MOV @R0+,@R1+ ; append front character to end. CMP #0,R0 ; null terminator means all consonants JEQ gotvowel JMP xferloop ; ; Reached a vowel -- append 'way' if we're still pointing ; at the first letter. Otherwise append 'ay'. ; R0 is pointing at the vowel. R1 is pointing at the end. ; gotvowel: CMP #0xe0,R0 ; still pointing at the first letter? JNE appenday MOV #'w',@R1+ appenday: MOV #'a',@R1+ MOV #'y',@R1+ MOV #0,@R1 ; null terminate CALL puts ; output the result JMP start ; ; Is the character @R0 a vowel? Set Z flag if so. ; vowel: CMP #'a',@R0 JEQ doret CMP #'e',@R0 JEQ doret CMP #'i',@R0 JEQ doret CMP #'o',@R0 JEQ doret CMP #'u',@R0 doret: RET
This time the code is done in line rather than as a CALL. It works by doing minimal copying of characters.
This code won't do the right thing if there are any spaces in the string gets reads. The idea is that a higher function would read a whole line and pick out words which it sends to this function to convert. ArdEx is a bit tight on memory, and I'm a bit lazy. Left as an exercise for the interested reader, etc.
All programs should work with a string typed at the keyboard.